
Abstract
해당 논문은 두 모델 (생성자와 판별자) 간의 경쟁 관계를 통해 training 데이터의 분포와 유사한 이미지를 생성하는 방법을 기술하고 있다
Model
Generative model
G 로 표기하며 training data 의 분포를 묘사한다. Discriminaive model 이 생성한 이미지를 구분하지 못하도록 학습한다.
Discriminative model
샘플 데이터가 진짜(학습 데이터) 인지 가짜(생성한 데이터) 인지 구분하는 모델이다. 진짜 데이터일 확률을 추정한다.
학습과정
- G는 D가 실제 데이터와 생성 데이터를 판별하는데 실수할 확률을 최대화 하는 방향으로 학습한다.
- minimax two player game
- D는 생성 데이터를 가짜로 잘 판별하는 것을 목표로 학습한다.
- G가 training 데이터 분포를 정확히 묘사할수록 D는 실제 데이터인지 생성데이터인지 구분하기 어려워진다 이는 곧 예측 확률이 1/2 에 가까워지는 것을 의미한다.
Introduction
- 기존의 Deep generative model 들은 최대 우도 추정(Maximum likelihood estimation) 과 관련된 전략들에서 발생하는 많은 확률 연산들을 근사하는데 발생하는 문제점과 비선형 활성화 함수들의 이점들을 가져오는 것에 한계점이 존재했음
- 해당 논문에서 소개되는 방법은 이러한 기존의 어려움을 회피하는 방법을 제시함
경쟁 관계
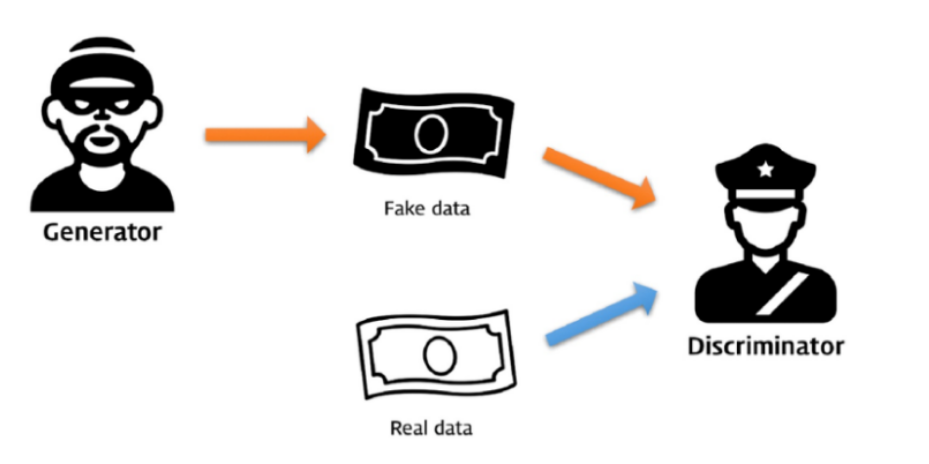
- GAN 의 경쟁하는 과정을 경찰과 위조지폐범 사이의 경쟁으로 비유하면, 위조지폐범은 최대한 진짜 같은 화폐를 만들어 경찰을 속이기 위해 노력, 경찰은 진짜 화폐와 가짜 화폐를 완벽히 판별하여 위조지폐범을 검거하는 것을 목표로 함
- 위와 같은 과정을 반복하여 경찰이 위조지폐를 구별할 수 있는 확률을 50%에 수렴하게 함으로써 실제 화폐와 위조 화폐를 구별할 수 없게 함
Adversarial nets

- 학습 초반에는 D(G(z)) 의 결과가 0에 가까움 (생성한 데이터가 형편없기 때문) 학습이 진행될 수록 D(G(z)) 의 값이 1이 되도록 발전함
- 첫번째 항: real data x 를 discriminator 에 넣었을 때 나오는 기대값
- 두번째 항: fake data z 를 generator 에 넣었을때 나오는 결과를 discriminator 에 넣엇을 때 나오는 기대값
생성자
function(D,G) 의 이상적인 결과는 두번째 항에서 D(G(z)) 가 1에 수렴하게 학습하는 것으로 총 함수의 output 값을 최소화 하는 방향으로 학습함
판별자
function(D, G) 의 이상적인 결과는 D(x) => 1 (1-D(G(z)) => 1 이 되는 것임 즉 총 결과값이 0이되는 방향이고 이는 곧 최댓값이 됨
학습과정

- k step 만큼 discriminator 를 학습한 이후 generator 를 학습함. inner loop 안에서 D를 완전히 최적화 시키는 것을 방지하고 제한된 데이터셋에서 overfitting 을 방지 하기 위함임.