
경사 하강 알고리즘이란
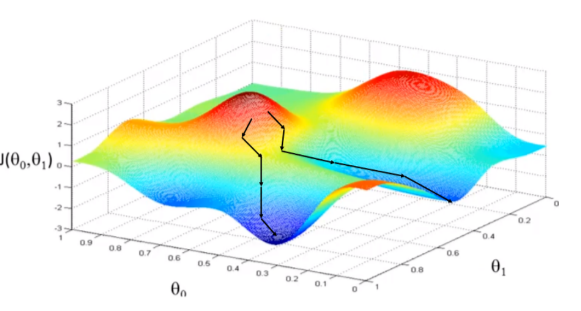
경사 하강 알고리즘은 비용 함수 J 를 최소화 하는 θ를 구하는 알고리즘입니다. 과정은 아래와 같습니다
- θ에 대해 임의의 초기값을 설정합니다.
- J 가 최소가 될때 가지 θ 갱신을 반복하며 최솟값에 도달했을 때 해당하는 θ 값을 찾습니다.
- 갱신 직전 값과 갱신 값이 같을 때 종료됩니다.

미분을 하는 이유
미분 값은 특정 지점에서의 기울기를 의미합니다. Global minima 지점이 있을 때 특정 θ 값에서 기울기가 양수이면 기울기의 반대 방향으로 θ 값을 변형시키면 최소값 지점으로 이동시킬 수 있습니다.
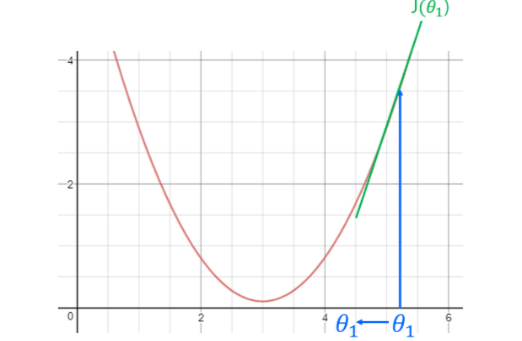
Learning Rate (학습 속도)
Learning Rate 가 지나치게 작을 때와 클 때를 비교해보겠습니다.
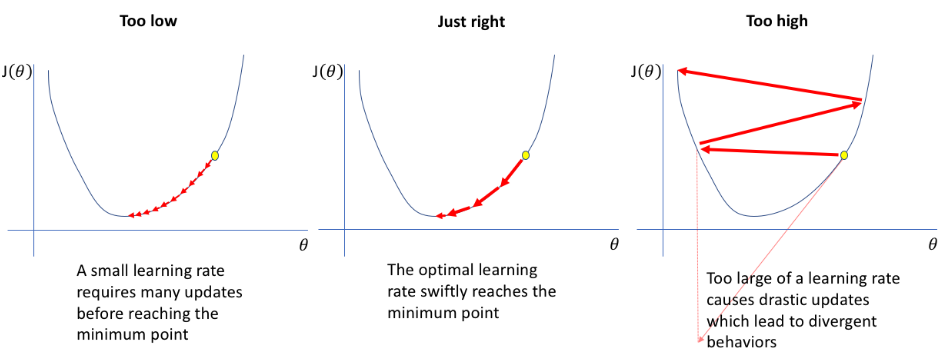
- Learning Rate가 지나치게 작으면 수렴하는데 너무 오랜 시간이 걸립니다.
- Learning Rate가 지나치게 크면 수렴하지 못하고 J값이 발산을 하여 학습이 불가능해질 수 있습니다.
- 이러한 이유로 적절한 Learning Rate를 초기화 하는 것은 매우 중요합니다.
Global minimum 과 local minimum

일반적인 등고선 그래프의 경우 전역 최솟값과 지역 최솟값이 존재합니다.
- 전역 최솟값: 등고선 전체에서 가장 작은 값
- 지역 최솟값: 특정 지역 내의 상대적인 최소값
- 초기값을 어떻게 설정하느냐에 따라서 Global Minimum 이 아닌 Local Minimum 에 빠져서 최적의 θ 값을 찾지 못할수도 있음
Linear Regression Case

선형 회귀의 경우네는 Bowl-Shaped Function 의 형태만을 가지기 때문에 Global mimimum 밖에 존재하지 않습니다.
Batch Gradient Descent
위에서 기술한 경사 하강 알고리즘이 Batch Gradient Descent 에 해당합니다. 여기서 말하는 Batch 란 Total Training set 입니다. 갱신을 하는 매 단계마다 전체 Training set 을 활용합니다. Gradient descent 알고리즘 자체는 loss function 을 입력 데이터 X에 대해서 편미분을 하는것이 아닌 가중치 W 에 대해서 편미분을 하는 것이기 때문에 기울기를 계산하는 것 자체는 입력데이터 갯수와 상관이 없습니다.
장점
- 전체 업데이트가 한번에 이뤄지므로 계산의 횟수가 적습니다
- 전체 데이터에 대해 미분값을 계산하여 갱신하므로 안정적입니다.
단점
- 한번의 갱신에 전체 Training set 가 사용되므로 학습이 오래걸립니다.
- 갱신 직전까지 Training set의 오차를 가지고 있어야 해서 상대적으로 많은 메모리가 요구됩니다.
- local minimum 에 빠지면 빠져나오기 어렵습니다.
Mini-batch Stochastic Gradient Descent
Batch Gradient Descent 의 단점을 보완하기 위해 나온 개념입니다. 전체 데이터 셋을 활용하는 대신 데이터 m 개에 대해서 각 데이터에 대한 기울기를 m 개 구한뒤 평균 기울기를 통해 모델을 업데이트 합니다.
장점
- Local optimal 에 빠질 리스크가 적다
- SGD 보다 병렬 처리에 유리하다
- 메모리 사용이 BGD 보다 적다
단점
- Batch size 에 따라 학습 효율이 달라진다
- SGD보다 메모리 사용이 높다.
- 학습할때의 수렴 방향이 뒤죽박죽이다.
Momentum

Momemtum 방식은 과거에 이동했던 방향을 기억하면서 해당 방향으로 일정 정도를 추가적으로 이동하는 방식이다. 이러한 방법은 SGD의 Oscilation 현상을 해결해줄 수 있습니다.
SGD는 중앙의 최적점으로 이동할때 한번의 step 에서 움직일 수 있는 step_size에 한계가 있어서 좌우로 계속 진동하며 수렴하지 못할 수 있다. 모멘텀을 사용할 경우 이전에 이동하던 방향에 대한 관성을 주어 빠르게 수렴할 수 있게 합니다.

또한 진행 방향에 대한 관성의 힘으로 Local mimimum 을 빠져나올수 있게한다. SGD의 경우 local minima 에 빠지면 gradient 가 0이 되어서 이동할 수 없지만 momentum 의 경우 beta 값을 이용해 빠져나올 수 있습니다.
Adagrad (Adaptive Gradient)
Adagrad 는 feature 마다 다른 학습률을 적용하는 기법입니다. Feature 마다 동일한 학습률을 적용하는 것은 비효율적이라는 가정아래 만들어진 개념입니다. AdaGrad 는 큰 기울기를 가져서 학습이 이미 많이 된 학습률은 감소시키고, 학습이 적게 된 다른 변수들은 잘 학습되도록 합니다.
다만 기울기 누적크기가 0 에 가까워져서 더 이상 학습이 진행되지 않을 수 있다. 이러한 문제점을 해결하기위해 RMSProp이 제안되었습니다.
RMSProp (Root Mean Square Propagation)
AdaGrad는 학습률이 꾸준히 감소하다보니 나중에는 0으로 수렴하여 학습이 더이상 진행되지 않는다는 한계점이 존재했습니다. RMSProp 은 이러한 한계점을 보완한 최적화 기법으로써 제프리 힌튼 교수가 코세라 강의중에 발표한 알고리즘입니다.
알고리즘 원리
- 지수이동평균(EMA)를 활용하여 기울기를 업데이트 합니다.
- 가장 최근 time step 에서의 기울기는 많이 반영하고 먼 과거의 time step 에서의 기울기는 조금만 반영합니다.
장점
- 변수마다 적절한 학습률을 적용하여 효율적인 학습을 진행할 수 있습니다
- AdaGrad 방식보다 상대적으로 학습을 오래 진행할 수 있습니다.
Adam(Adaptive Momentum Estimation)
Momentum 과 RMSProp 의 장점을 결합한 알고리즘입니다.
Momentum 의 장점은 아래와 같습니다.
- 학습 방향정보를 기반으로 Non convex function 과 saddle point 에서 벗어날 수 있도록 도와줍니다.
RMSProp 의 장점은 아래와 같습니다.
- 피처마다 다른 학습률을 적용하여 효율적으로 학습을 진행할 수 있도록 도와주되 gradient 가 0에 수렴하는것을 방지합니다.
수식
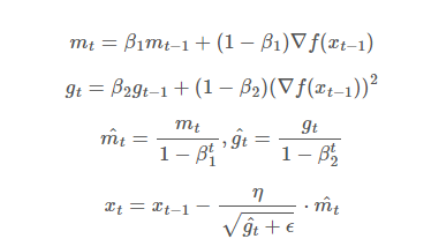
- B1: Momentum 의 지수 평균 이동: 0.9
- B2: RMSProp 의 지수평균 이동: 0.999
- m, g 학습 초기시 mt gt 가 0이 되는 것을 방지하기 위한 값
- e: 분모가 0이되는 것을 방지하기 위한 작은 값 : 10^-8
- n: 학습률: 0.001
참고
https://light-tree.tistory.com/133
https://www.jeremyjordan.me/nn-learning-rate/
https://box-world.tistory.com/7
https://shuuki4.github.io/deep%20learning/2016/05/20/Gradient-Descent-Algorithm-Overview.html
'인공지능' 카테고리의 다른 글
| [인공지능] - Accuracy, Precision, Recall, F1-Score (0) | 2024.02.07 |
|---|