
개요
데이터베이스간의 데이터를 분리할 경우 데이터베이스 하나의 트랜잭션을 사용하여 상태 변화를 ACID 원칙에 따라서 보장할 수 없다. 이를 해결하기 위한 방안이 있다
Two Phase Commit
여러 노드들 상에서의 원자적 트랜잭션 커밋을 이루기 위한 알고리즘 또는 프로토콜
탄생 배경
싱글 노드에서 실행되는 데이터베이스의 원자성은 보통 스토리지 엔진에 의해 구현됨. 클라이언트가 데이터베이스 노드에 요청하면, 데이터베이스는 트랜잭션이 durable 하게 write 될 수 있도록 보장함 (write-ahead. log) 만약 쓰기 연산이 실패하면 log 로 부터 트랜잭션을 recovery 함.
싱글 노드 상에서, 트랜잭션 커밋은 데이터가 디스크에 쓰여진 순서에 의존하게됨. 트랜잭션의 성공여부는 커밋 레코드가 디스크에 write되는 순간에 결정됨
분산 데이터 저장소
대부분의 NoSQL 은 분산 트랜잭션을 지원하지 않지만. 다양한 클러스터 시스템은 이를 지원하고 있음 클러스터 시스템에서 싱글 노드와 같은 방식만으로 트랜잭션을 지원한다면 아래와 같은 문제가 발생 가능함
- 일부 노드에서는 커밋 성공, 일부 노드에서는 실패
위와 같이 일부노드만 커밋하고 일부노드는 하지 않는다면, 노드들의 데이터는 일관되지 않음. 즉, 하나의 노드는 트랜잭션의 모든 노드들이 커밋하는게 확실한 순간에 한번 커밋해야함.
동작 원리
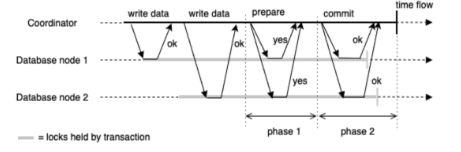
2PC 는 일반적인 싱글 노드 트랜잭션에 존재하지 않는 새로운 컴포넌트인 코디네이터를 사용. 코디네이터는 트랜잭션을 요청하는 같은 애플리케이션 프로세스 내 라이브러리에 구현되어 있으나. 분리된 서비스나 프로세스일수도 있음.
- 애플리케이션이 여러 데이터베이스에 쓰기 요청 & 코디네이터에 트랜잭션 ID 요청 (Global Unique)
- 애플리케이션이 각 참여자와 싱글 노드 트랜잭션을 시작하고 유니크한 ID 전달
- 애플리케이션이 커밋할 준비가 되면 모든 참여자들에게 글로벌 유니크 트랜잭션 ID 가 포함된 prepare 요청 전송
- 모든 prepare 요청들에 대한 응답들을 받으면, 트랜잭션을 커밋할지 abort 할지 결정함. 코디네이터는 그러한 결정을 디스크에 존재하는 코디네이터 로그에 기록하여 crash 에 대비 (commit point)
- 코디네이터의 결정이 디스크에 write 되고 커밋 혹은 abort 요청이 모든 참여자에게 전달
- 실패 혹은 타임아웃이면 성공할때까지 retry
특징 (번복 할 수 없음)
- 참여자 모두가 yes 로 응답할 시 반드시 커밋함
- 코디네이터가 한번 결정하면 반드시 결정을 강제해야함
- 이러한 두가지 번복할 수 없는 결정으로 atomic 보장
취약점
코디네이터가 다운 될 경우에 prepare 이후의 상황은 코디네이터의 도움없이 abort 할수가 없음 => 코디네이터 노드가 다시 alive 될 때 까지 기다려야함
'데이터베이스' 카테고리의 다른 글
| [MongoDB] - MongoDB Replicaset (0) | 2024.01.10 |
|---|---|
| [데이터베이스] - DBCP(Database Connection Pool) (0) | 2024.01.10 |
| [데이터베이스] - 2PL 과 LOCK (0) | 2024.01.04 |
| [데이터베이스] - 트랜잭션 동시성 제어 (2) (1) | 2024.01.04 |
| [데이터베이스] - 트랜잭션 동시성 제어 (1) (0) | 2024.01.04 |